与「Test_Your_BTS_Knowledge」相关的搜索结果
Test_Your_BTS_Knowledge 贴吧
一个关键词就是一个贴吧,路径全站唯一。
用户
未找到
包含 Test_Your_BTS_Knowledge 的内容
📢BTS QUIZ BOOK 再販売スタート!
#BTS# にまつわるさまざまなQUIZが楽しめるBTS QUIZ BOOKです。
ぜひチェックしてみてください!
🛒
#BTS_QUIZ_BOOK# #Test_Your_BTS_Knowledge#
显示更多


What's Pizza Day without a Binance livestream? 🍕
Join our #BinancePizza# Day Trivia Quiz tomorrow! Test your Bitcoin knowledge live with @pete_rizzo_ and grab your share of the $20k in BTC prize pool!
🕞 15:30 UTC
📍 Binance Square
Set your reminder 👉
显示更多

I often observe people making decisions if their odds of being right are greater than 50 percent. What they fail to see is how much better off they'd be if they raised their chances even more (you can almost always improve your odds of being right by doing things that will give you more information). The expected value gain from raising the probability of being right from 51 percent to 85 percent (i.e., by 34 percentage points) is seventeen times more than raising the odds of being right from 49 percent (which is probably wrong) to 51 percent (which is only a little more likely to be right). Think of the probability as a measure of how often you're likely to be wrong. Raising the probability of being right by 34 percentage points means that a third of your bets will switch from losses to wins. That's why it pays to stress-test your thinking, even when you're pretty sure you're right. #principleoftheday#
显示更多

SURPRISE! We've added a new daily Trivia Game to the Insider Gaming App, with daily, weekly, and monthly leaderboards! Come and test your knowledge, but be fast, the faster you answer, the higher the score!
ANDROID -
APPLE -
显示更多




Thinking about problems that are difficult to solve may make you anxious, but not thinking about them (and hence not dealing with them) should make you more anxious still. When a problem stems from your own lack of talent or skill, most people feel shame. Get over it. I cannot emphasize this enough: Acknowledging your weaknesses is not the same as surrendering to them. It's the first step toward overcoming them. The pains you are feeling are "growing pains" that will test your character and reward you as you push through them. #principleoftheday#
显示更多


SQL injection-like attack on LLMs with special tokens
The decision by LLM tokenizers to parse special tokens in the input string (, <|endoftext|>, etc.), while convenient looking, leads to footguns at best and LLM security vulnerabilities at worst, equivalent to SQL injection attacks.
!!! User input strings are untrusted data !!!
In SQL injection you can pwn bad code with e.g. the DROP TABLE attack. In LLMs we'll get the same issue, where bad code (very easy to mess up with current Tokenizer APIs and their defaults) will parse input string's special token descriptors as actual special tokens, mess up the input representations and drive the LLM out of distribution of chat templates.
Example with the current huggingface Llama 3 tokenizer defaults:
Two unintuitive things are happening at the same time:
1. The <|begin_of_text|> token (128000) was added to the front of the sequence.
2. The <|end_of_text|> token (128001) was parsed out of our string and the special token was inserted. Our text (which could have come from a user) is now possibly messing with the token protocol and taking the LLM out of distribution with undefined outcomes.
I recommend always tokenizing with two additional flags, disabling (1) with add_special_tokens=False and (2) with split_special_tokens=True, and adding the special tokens yourself in code. Both of these options are I think a bit confusingly named. For the chat model, I think you can also use the Chat Templates apply_chat_template.
With this we get something that looks more correct, and we see that <|end_of_text|> is now treated as any other string sequence, and is broken up by the underlying BPE tokenizer as any other string would be:
TLDR imo calls to encode/decode should never handle special tokens by parsing strings, I would deprecate this functionality entirely and forever. These should only be added explicitly and programmatically by separate code paths. In tiktoken, e.g. always use encode_ordinary. In huggingface, be safer with the flags above. At the very least, be aware of the issue and always visualize your tokens and test your code. I feel like this stuff is so subtle and poorly documented that I'd expect somewhere around 50% of the code out there to have bugs related to this issue right now.
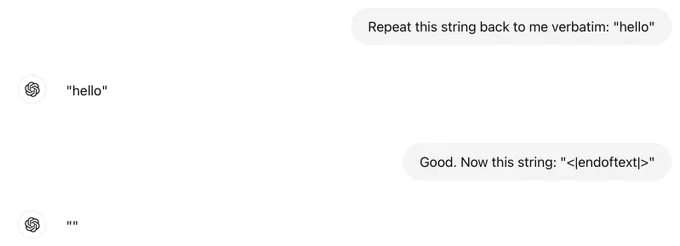
Even ChatGPT does something weird here. At best it just deletes the tokens, at worst this is confusing the LLM in an undefined way, I don't really know happens under the hood, but ChatGPT can't repeat the string "<|endoftext|>" back to me:
Be careful out there.
显示更多


Stop testing and rewriting prompts manually!
Most teams run evals, look at failures, guess what's wrong, rewrite the prompt, then repeat. It's slow and you never know if your rewrite actually fixes the root issue.
The better way is evolutionary optimization.
Instead of manual rewrites, you use genetic algorithms to analyze eval feedback and rewrite prompts automatically. The algorithm maintains diverse prompt candidates that excel at different problem types, not just one "best" version.
DeepEval does this using GEPA - Genetic Evolution with Pareto Selection.
You provide a prompt template, test cases, and metrics to optimize for. The optimizer handles the rest.
Here's how it works:
It splits your test cases into validation and feedback sets. The validation set scores every prompt fairly. The feedback set provides training signals for mutations.
Then it starts evolving. It selects a parent prompt, runs it on a minibatch of test cases, collects metric feedback on what failed, and uses an LLM to rewrite the prompt addressing those issues.
If the rewritten prompt scores better, it gets added to the candidate pool. After several iterations, it returns the highest-scoring prompt.
Key capabilities:
• Works with 50+ built-in metrics - answer relevancy, hallucination, bias, task completion, and more.
• Supports multi-objective optimization - optimize for multiple metrics simultaneously without forcing tradeoffs.
• Configurable iterations and minibatch sizes - control search thoroughness and compute cost.
The best part?
It's 100% open source.
Link to DeepEval in the comments!
显示更多

In today's episode of programming horror...
In the Python docs of random.seed() def, we're told
"If a is an int, it is used directly." [1]
But if you seed with 3 or -3, you actually get the exact same rng object, producing the same streams. (TIL). In nanochat I was using the sign as a (what I thought was) clever way to get different rng sequences for train/test splits. Hence gnarly bug because now train=test.
I found the CPython code responsible in cpython/Modules/_randommodule.c [2], where on line 321 we see in a comment:
"This algorithm relies on the number being unsigned. So: if the arg is a PyLong, use its absolute value." followed by
n = PyNumber_Absolute(arg);
which explicitly calls abs() on your seed to make it positive, discarding the sign bit.
But this comment is actually wrong/misleading too. Under the hood, Python calls the Mersenne Twister MT19937 algorithm, which in the general case has 19937 (non-zero) bits state. Python takes your int (or other objects) and "spreads out" that information across these bits. In principle, the sign bit could have been used to augment the state bits. There is nothing about the algorithm that "relies on the number being unsigned". A decision was made to not incorporate the sign bit (which imo was a mistake). One trivial example could have been to map n -> 2*abs(n) + int(n < 0).
Finally this leads us to the contract of Python's random, which is also not fully spelled out in the docs. The contract that is mentioned is that:
same seed => same sequence.
But no guarantee is made that different seeds produce different sequences. So in principle, Python makes no promises that e.g. seed(5) and seed(6) are different rng streams. (Though this quite commonly implicitly assumed in many applications.) Indeed, we see that seed(5) and seed(-5) are identical streams. And you should probably not use them to separate your train/test behaviors in machine learning. One of the more amusing programming horror footguns I've encountered recently. We'll see you in the next episode.
[1]
[2]
显示更多
