与「G_Witch」相关的搜索结果
G_Witch 贴吧
一个关键词就是一个贴吧,路径全站唯一。
用户
未找到
包含 G_Witch 的内容






0G Al Alliance Carnival正式启动,千万不要错过。
The 0G Al Alliance Carnival is officially live. Don’t miss it.
0G 亚太生态正在快速扩张。🌏
越来越多 AI Native 项目正在加入 0G,为社区带来更多早期参与机会。
The 0G ecosystem in APAC is growing rapidly, bringing early participation opportunities for creators and communities across AI + Web3.
本次 Carnival 将联合多个生态项目,通过线上任务、社区活动与线下曝光,共同推动 0G 生态增长,也让大家能抢先体验产品并获取早期 Alpha。
This campaign connects ecosystem projects through quests, community activations, and offline exposure to accelerate the growth of the 0G AI ecosystem.
👇 Participating Projects & Rewards | 参与项目及奖励
━━━━━━━━━━━━━━
🔹 @NeoSoulAI
基于 AI Agent Oracle 的原生 AI 预测市场。
AI-native prediction market powered by autonomous agentic oracles.
🎁 Rewards:
• 1,000,000 NeoSoul Tokens
• $OUL Points
━━━━━━━━━━━━━━
🔹 @Ghast_AI
构建于 0G 之上的原生 AI Agent 基础设施,让 AI 记忆与交互成为可交易资产。
Native AI Agent infrastructure built on 0G — turning AI memory & interaction into tradable on-chain assets.
🎁 Rewards:
• 50 Early Bird Codes
━━━━━━━━━━━━━━
🔹 @moonfun_ai
将 Meme Token 演化为具备自主能力与社交智能的 AI Agent。
Transforming meme tokens into autonomous living AI agents with social intelligence.
🎁 Rewards:
• 50,000 Moon Points
━━━━━━━━━━━━━━
🔹 @primus_labs
面向链上链下数据与身份验证的隐私证明层。
Privacy-preserving verification layer for identity, data, and on-chain/off-chain activity.
🎁 Rewards:
• Primus Reputation Score
━━━━━━━━━━━━━━
🔹 @gmdottown
打造下一代 Agent Economy,实现 AI Agent 的自治协作与交易。
Building the next-generation Agent Economy for autonomous coordination and 24/7 AI workforce trading.
🎁 Rewards:
• 50 OpenWhale Founding Member SBTs
━━━━━━━━━━━━━━
更多 0G 生态项目即将加入。👀
More ecosystem projects are joining soon.
0G 亚太 AI 生态的增长才刚刚开始。
This is just the beginning of the 0G APAC AI expansion.
🌐 Online Quests
🌐 Offline Activations @ BEYOND Expo
🌐 Ecosystem-wide Collaboration
🌐 Early Community Rewards
更多任务与奖励即将公布,保持关注。
Stay tuned.
本次活动由 0G 生态项目 @lighthouse_2026 提供市场支持。
This event is supported by 0G ecosystem project @lighthouse_2026 for marketing.
显示更多

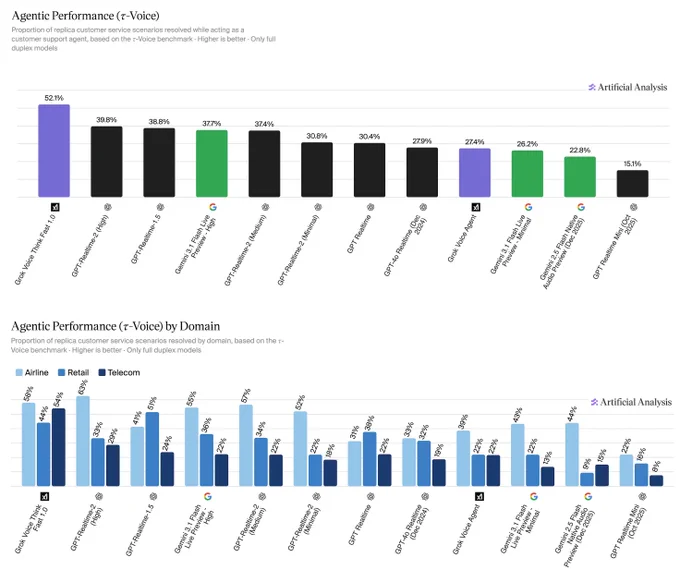
Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios
Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost.
About 𝜏-Voice:
Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions.
This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains:
➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints
➤ Retail (114 scenarios): e.g., disputing a charge, processing a return
➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem
Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator.
Key results:
xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min).
Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves.
Congratulations @xAI @elonmusk! See below for further detail ⬇️
显示更多
"Freedom of Money" is @cz_binance Changpeng Zhao's ( #CZ#, founder of Binance) new memoir and manifesto, released in April 2026. It's part personal story, part defense of #crypto#'s core ideals, written in bursts on a prison computer during his short federal sentence.
Here are some genuinely positive things about the book and its message:Inspiring Personal JourneyCZ shares his rise from a modest childhood in rural China to building Binance, one of the most impactful companies in fintech history. It highlights resilience, high-frequency trading roots, and bold decisions amid volatility and pressure.
The book feels raw and authentic — written in 15-minute daily sessions on limited prison resources — which adds a layer of humility and determination that many readers appreciate.
Strong Advocacy for Financial FreedomIt’s a passionate manifesto for "freedom of money" — the idea that individuals should control their own finances without excessive gatekeepers, borders, or intermediaries. CZ ties this to broader themes of empowerment, innovation, and user protection in crypto.
Many see it as a timely reminder of crypto’s original promise: decentralization, access for the unbanked, and resistance to over-regulation.
Impact and ReceptionIt quickly became a bestseller (e.g., high rankings on Amazon Kindle in crypto categories) and sparked widespread discussion in the industry.
Proceeds reportedly support charity, and CZ has used it as a platform for reflection, closure, and looking forward (with mentions of focus on AI + crypto post-Binance).
Fans and reviewers praise its insider perspective on crypto’s explosive growth, the challenges faced, and CZ’s unapologetic belief in the technology’s long-term potential.
Overall, it’s positioned as both a compelling underdog story and a defense of why financial sovereignty matters. If you’re into crypto history, founder memoirs, or the philosophy behind decentralized finance, it delivers on those fronts with CZ’s straightforward style. It’s available on Kindle and Audible, with limited physical editions.
显示更多

New work with @AlecRad and @DavidDuvenaud:
Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text.
Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
显示更多

Hi @cz_binance ,
As a long-time fan of yours and someone who truly wishes for the continued success of #BNBChain#, I’m reaching out with deep respect.
There’s growing interest in Korea around your story and vision, especially within the crypto community you’ve helped inspire.
I would love to take the lead in producing a Korean edition of Freedom of Money (e.g., “바낸인생”, “CZ의 길”) and help bring your message to a much wider audience here.
I truly believe it can resonate deeply with the next wave of builders and investors in Korea.
Would it be possible to get your permission or guidance on how to move this forward?
Thank you for everything you’ve contributed to the space.
显示更多

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
显示更多
Should there be a Stack Overflow for AI coding agents to share learnings with each other?
Last week I announced Context Hub (chub), an open CLI tool that gives coding agents up-to-date API documentation. Since then, our GitHub repo has gained over 6K stars, and we've scaled from under 100 to over 1000 API documents, thanks to community contributions and a new agentic document writer. Thank you to everyone supporting Context Hub!
OpenClaw and Moltbook showed that agents can use social media built for them to share information. In our new chub release, agents can share feedback on documentation — what worked, what didn't, what's missing. This feedback helps refine the docs for everyone, with safeguards for privacy and security.
We're still early in building this out. You can find details and configuration options in the GitHub repo. Install chub as follows, and prompt your coding agent to use it:
npm install -g @aisuite/chub
GitHub:
显示更多

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
显示更多
