

Artificial Analysis (@ArtificialAnlys)
@ArtificialAnlys
Independent analysis of AI
645 正在关注 105.3K 粉丝
GLM-5.2 leads open weights models and sits at #3# overall on GDPval-AA, a real-world agentic work benchmark
GLM-5.2 from @Zai_org scores 1524 Elo on GDPval-AA, which measures performance on real-world, economically valuable knowledge work through long-horizon, multi-turn tasks.
Key takeaways:
➤ #3# overall, behind only Claude Fable 5 (1783) and Claude Opus 4.8 (1615), and level with GPT-5.5 (xhigh, 1509)
➤ The leading open weights model by a wide margin: the next open model, MiniMax-M3, scores 1408
➤ Ahead of many proprietary models, including Google's Gemini 3.5 Flash (1357), Qwen 3.7 Max (1289), Muse Spark (1158)
➤ The tasks are agentic. GLM-5.2 averaged ~31 turns per task across 1,999 matches
➤ Consistent with the rest of its launch, GLM-5.2 also leads open weights on the Artificial Analysis Intelligence Index, ranks #3# on the Agentic Index, and #3# on AA-Briefcase
显示更多

Cursor Composer 2.5's is 3–18x cheaper than Opus 4.7 in Claude Code (medium reasoning), and 5–32x cheaper than GPT-5.5 in Codex (medium) based on API pricing
This low Cost per Task isn't just driven by relatively low token pricing, it's also driven by low relatively low token usage compared to other leading models. @cursor_ai Composer 2.5 only used 1.6M token to complete our Coding Agent Index benchmarks, while other models used up to 5.7M.
This lower token usage also contributes to a low Time per Task. Across the Coding Agent Index configurations shown, average Time per Task was ~12 minutes. Composer 2.5 completed tasks in ~9 minutes on average, making it ~1.3x faster than average, while Composer 2.5 Fast completed tasks in ~7 minutes, making it ~1.8x faster than the average across agents.
Link to full benchmark results below
显示更多

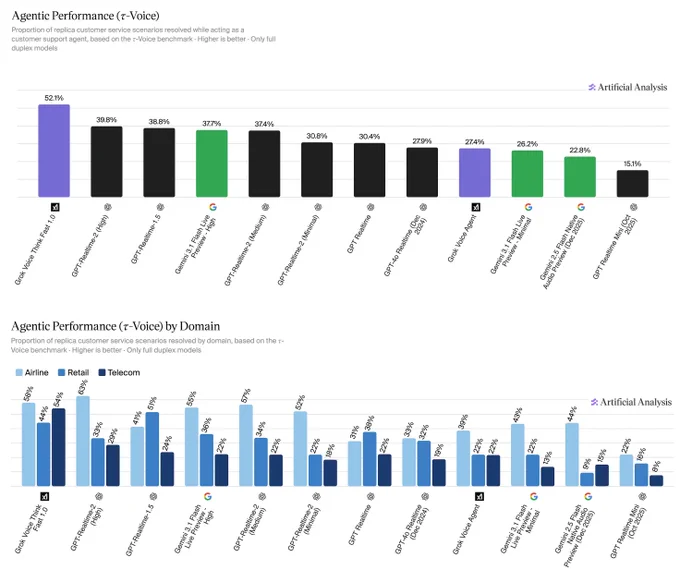
Announcing agentic performance benchmarking for Speech to Speech models on Artificial Analysis. We use 𝜏-Voice to measure tool calling and customer interaction voice agent capabilities in realistic customer service scenarios
Even the strongest Speech to Speech (S2S) models today resolve only about half of realistic customer service scenarios end-to-end - a meaningful gap relative to frontier text-based agents on the same tasks. Voice channels introduce significant complexity: challenging accents, background noise, and packet loss, all while requiring fast responses, consistency across long multi-turn conversations, and reliable tool use. Performance also varies considerably by audio condition: in clean audio some models perform notably better, but realistic conditions continue to pose a challenge. Conversation duration also varies meaningfully across models, with implications for both customer experience and operational cost.
About 𝜏-Voice:
Our Agentic Performance benchmark is based on 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026), which extends 𝜏²-bench into the voice modality to evaluate S2S models on realistic customer service tasks. It measures multi-turn instruction following, support of a simulated customer through a complete interaction, and tool use against simulated customer service systems. The simulated user combines an LLM-driven decision model with realistic audio synthesis: diverse accents, background noise, and packet loss modelled on real network conditions.
This complements our Big Bench Audio benchmark measuring intelligence and Conversational Dynamics (Full Duplex Bench subset) benchmark measuring conversational naturalness. Scores are the average of three independent pass@1 trials. We evaluate under realistic audio conditions using the 𝜏²-bench base task split across three domains:
➤ Airline (50 scenarios): e.g., changing a flight, rebooking under policy constraints
➤ Retail (114 scenarios): e.g., disputing a charge, processing a return
➤ Telecom (114 scenarios): e.g., resolving a billing issue, troubleshooting a service problem
Task success is determined by deterministic checks against expected actions and final database state, consistent with the 𝜏²-bench evaluator.
Key results:
xAI's Grok Voice Think Fast 1.0 is the clear leader at 52.1%, averaging 5.6 minutes per conversation, the second-longest overall. OpenAI's GPT-Realtime-2 (High) (39.8%, 3.0 min) and GPT-Realtime-1.5 (38.8%, 4.8 min) follow, with Gemini 3.1 Flash Live Preview - High close behind at 37.7% (3.8 min).
Speech to Speech is a fast evolving modality and we expect movement in rankings as we continue to add new models with these capabilities, and model robustness improves.
Congratulations @xAI @elonmusk! See below for further detail ⬇️
显示更多
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
显示更多
