

at this point, put your cat on cursor and see what it builds.
it could build the next $1B SaaS 🤷♂️
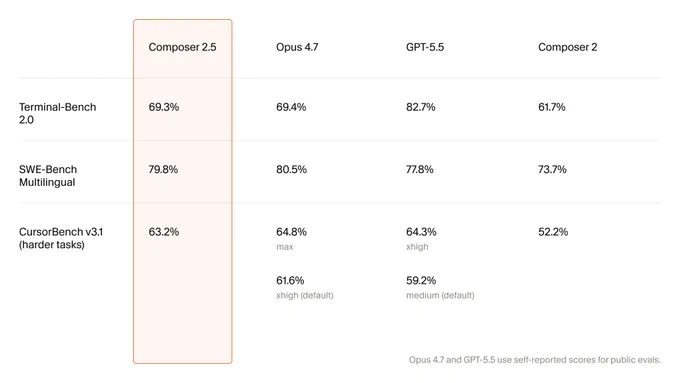
Composer 2.5 is now the most-chosen model in Cursor.
We're giving everyone 10x usage for the rest of the day. Enjoy!
(unaffiliated thoughts)
@umbrel should have a cloud offering.
i’m not tin-foil hat enough to self-host on a box that lives in my house, and while i’m perfectly capable, i have no desire to configure and manage a VPS
显示更多
the team did an internal test of this model last week
the whole company (bar a few exceptions) had all their cursor chats redirected to composer 2.5 for like 2 days.
i didn't even notice, which I think is testament to the progress of this model. go use it, its very good.
显示更多
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
显示更多
cursor started out as a CAD software before the big bosses pivoted to coding
that being said, i call on my small audience to ask - what is the “cursor for CAD” today?
where can i prompt an AI and get a good, printable 3D model out of the other end!
显示更多
god damn i’d buy all of these today
in black though only
that white bag is getting ruined in a week
ChatGPT is allowing me to imagine all the stuff I want @nothing to make.




i’ve ironically found models to be less caring about restrictions and ethics the less context / input you give them
rays example is a good one - legit use case but the model pushes back
whereas “there’s been a npm hack, check if i’m cooked” probably would’ve been fine
显示更多
Anthropic blocked me from checking if my own laptop was safe during a real npm attack.

i use this model
i use this model exclusively for any ui work i might do
even if you skip the text, the charts tell the story!
both on outright intelligence and cost efficiency, Cursor frequently comes out on top, performing better than the model's own harnesses
this is why people resolve with Cursor as their tool of choice 💪
显示更多
Announcing the Artificial Analysis Coding Agent Index! Our new coding agent benchmarks measure how combinations of agent harnesses and models perform on 3 leading benchmarks, token usage, cost and more
When developers use AI to code they’re choosing a model, but also pairing it with a specific harness. It makes sense to benchmark that combination to understand and compare performance.
The Artificial Analysis Coding Agent Index includes 3 leading benchmarks that represent a broad spectrum of coding agent use:
➤ SWE-Bench-Pro-Hard-AA, 150 realistic coding tasks that frontier models struggle with, sampled from Scale AI’s SWE-Bench Pro
➤ Terminal-Bench v2, 84 agentic terminal tasks from the Laude Institute and that range from system administration and cryptography to machine learning. 5 tasks were filtered due to environment incompatibility
➤ SWE-Atlas-QnA, 124 technical questions developed by Scale AI about how code behaves, root causes of issues, and more, requiring agents to explore codebases and give text answers
Analysis of results:
➤ Opus 4.7 and GPT-5.5 lead the Index: Opus 4.7 in Cursor CLI scores 61, followed closely by GPT-5.5 in Codex and Opus 4.7 in Claude Code at 60. GPT-5.5 in Cursor CLI follows at 58.
➤ Open weights models are competitive, but still trail the leaders: GLM-5.1 in Claude Code is the top open-weight result at 53, followed by Kimi K2.6 and DeepSeek V4 Pro in Claude Code at 50. These are strong results, but still meaningfully behind the top proprietary models.
➤ Gemini 3.1 Pro in Gemini CLI underperforms: Gemini 3.1 Pro in Gemini CLI scores 43, well below where Gemini 3.1 Pro sits on our Intelligence Index, highlighting that Gemini’s performance in Gemini CLI remains a relative weak spot for Google’s offering.
➤ Cost per task (API token pricing) varies >30x: Composer 2 in Cursor CLI is cheapest at $0.07/task, followed by DeepSeek V4 Pro in Claude Code at $0.35/task and Kimi K2.6 in Claude Code at $0.76/task. At the high end, GPT-5.5 in Codex costs $2.21/task, while GLM-5.1 in Claude Code costs $2.26/task. For both models this was contributed to by high token usage, and in GPT-5.5’s case by a relatively higher per token cost.
➤ Token usage varies >3x: GLM-5.1 in Claude Code uses the most tokens at 4.8M/task, followed by Kimi K2.6 at 3.7M/task and DeepSeek V4 Pro at 3.5M/task. GPT-5.5 in Codex uses 2.8M tokens/task, substantially more than Opus 4.7 in Claude Code at 1.7M/task. In GLM-5.1’s case, higher token usage, cost and execution time were partly driven by the model entering loops on some tasks.
➤ Cache hit rates remain high but vary materially: Cache hit rates range from 80% to 96% across combinations. Provider routing, harness prompt structure and cache behavior can materially change the economics of running the same model given cached inputs are typically <50% the API price of regular input tokens.
➤ Time per task varies >7x: Opus 4.7 in Claude Code is fastest at ~6 minutes/task, while Kimi K2.6 in Claude Code is slowest at ~40 minutes/task. This is contributed to by differences in average turns per task, token usage and API serving speed. Opus 4.7 had materially lower amount of turns to complete a task than all other models while Kimi K2.6 had the most.
➤ Cursor made real progress with Composer 2: Composer 2 in Cursor CLI scores 48, near the leading open-weight model results, while being the cheapest combination measured at $0.07/task. Cursor has stated Composer 2 is built from Kimi K2.5, showcasing they have made substantial post-training gains.
This is just the start. We are planning to add additional agents (both harnesses and models). Let us know what you would like to see added next.
显示更多

I'd have never guessed that I'm back to using Cursor
put this in the next iPhone + the cherry red colour from the leaks and i’m buying day 1
Tianma has unveiled a panel with an ultra-narrow bezel of just 0.35mm.
6.32 inches, 240Hz.
Guess which brand will get this screen?

is the bit with the label considered the “top”, or is the side where the device sits the top (even though there’s no screen)
the whoop seems to design itself to be worn tech on top afaik, but this seems ambiguous 🤔
显示更多


if we make a merch bottle i really hope it’s not that big
add it to the list of “items i can’t put on the fold out table of a ryanair flight” alongside my macbook pro

soon they may run long enough to love you back 🤗
cursor long running agents
I am starting to fall in love
don’t even get me started on this topic
sorry, how is this even legal? how can they change the interest rate on a student loan depending on how much you earn??
